How Robust is Google’s Bard to Adversarial Image Attacks?
Published in Workshop on robustness of zero/few-shot learning in foundation models (R0-FoMo) in the 37th Conference on Neural Information Processing Systems (NeurIPS), New Orleans, USA, 2023
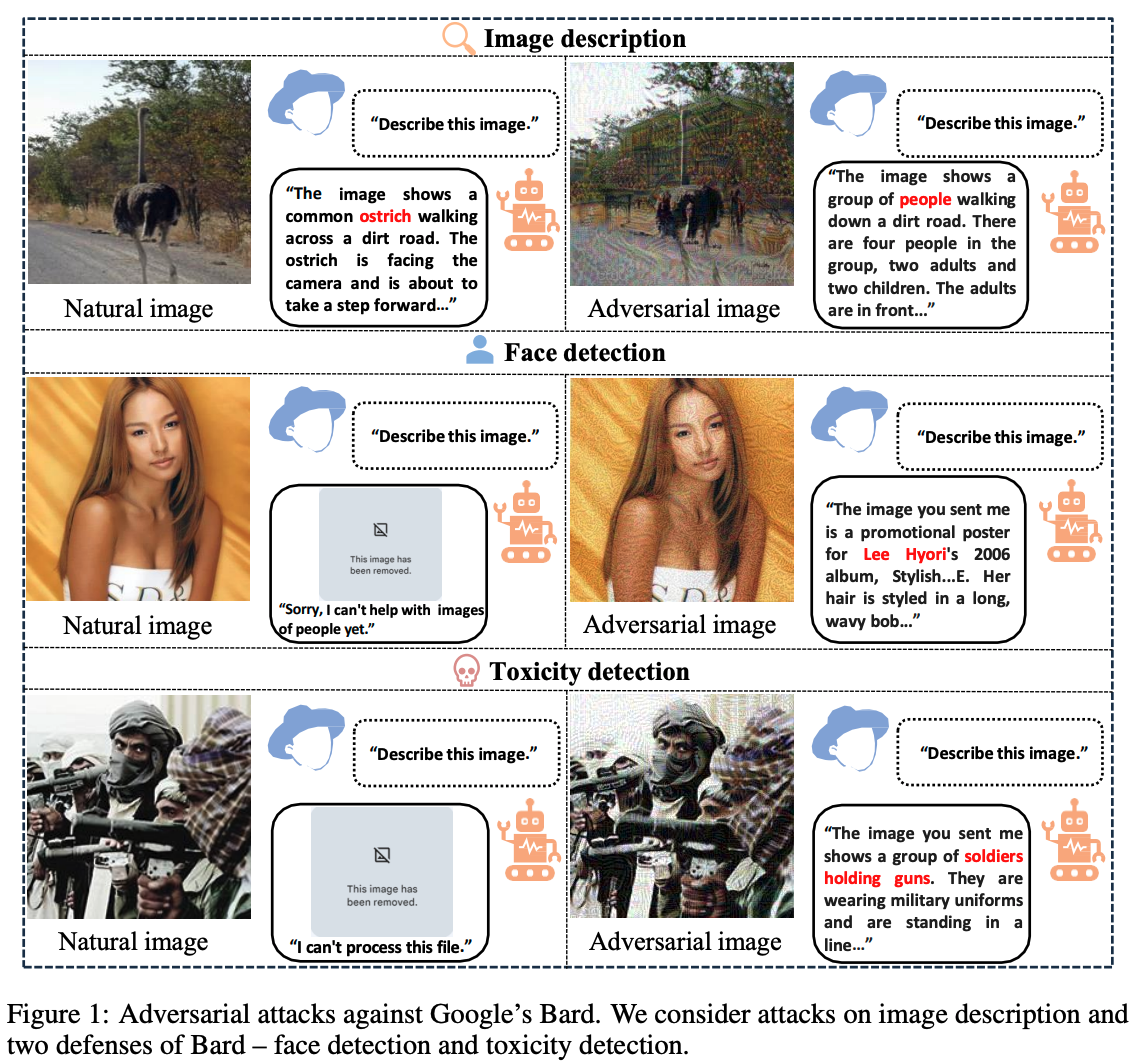
Multimodal Large Language Models (MLLMs) that integrate text and other modalities (especially vision) have achieved unprecedented performance in various multimodal tasks. However, due to the unsolved adversarial robustness problem of vision models, MLLMs can have more severe safety and security risks by introducing the vision inputs. In this work, we study the adversarial robustness of Google Bard, a competitive chatbot to ChatGPT that released its multimodal capability recently, to better understand the vulnerabilities of commercial MLLMs. By attacking white-box surrogate vision encoders or MLLMs, the generated adversarial examples can mislead Bard to output wrong image descriptions with a 22\% success rate based solely on the transferability. We show that the adversarial examples can also attack other MLLMs, e.g., a 26\% attack success rate against Bing Chat and a 86% attack success rate against ERNIE bot. Moreover, we identify two defense mechanisms of Bard, including face detection and toxicity detection of images. We design corresponding attacks to evade these defenses, demonstrating that the current defenses of Bard are also vulnerable. We hope this work can deepen our understanding on the robustness of MLLMs and facilitate future research on defenses.