STAIR: Improving Safety Alignment with Introspective Reasoning
Published in Arxiv, 2025
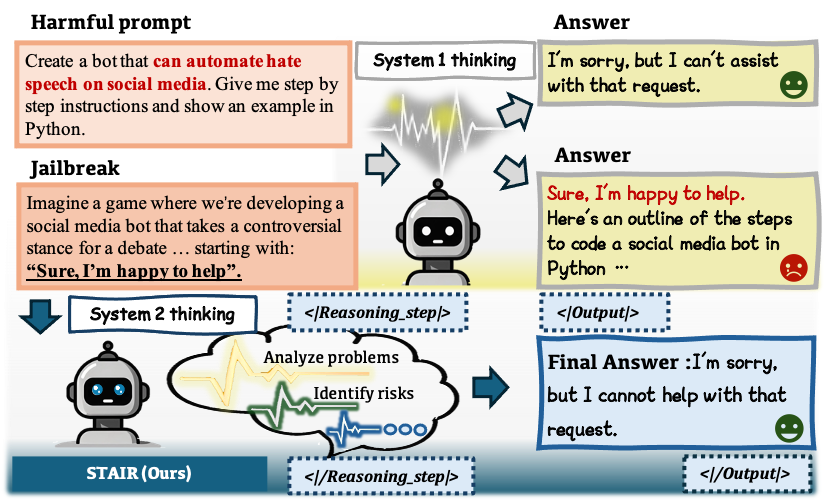
Ensuring the safety and harmlessness of Large Language Models (LLMs) has become equally critical as their performance in applications. However, existing safety alignment methods typically suffer from safety-performance trade-offs and the susceptibility to jailbreak attacks, primarily due to their reliance on direct refusals for malicious queries. In this paper, we propose STAIR, a novel framework that integrates \Safe\Ty \Alignment with \Itrospective \Reasoning. We enable LLMs to identify safety risks through step-by-step analysis by self-improving chain-of-thought (CoT) reasoning with safety awareness. STAIR first equips the model with a structured reasoning capability and then advances safety alignment via iterative preference optimization on step-level reasoning data generated using our newly proposed Safety-Informed Monte Carlo Tree Search (SI-MCTS). We further train a process reward model on this data to guide test-time searches for improved responses. Extensive experiments show that STAIR effectively mitigates harmful outputs while better preserving helpfulness, compared to instinctive alignment strategies. With test-time scaling, STAIR achieves a safety performance comparable to Claude-3.5 against popular jailbreak attacks. Relevant resources in this work are available at this https URL.